
Google Search Console から「robots.txt によりブロックされました」という理由でエラーの通知がありました。しかしそのページは検索結果に表示させたくなかったためクローラーに対象外とするように設定したページだったため、ブロックされたままで良かったのです。
「ブロックされたままでOK」という場合の対処法をご紹介します。
目次
事の発端はGoogle Search Consoleからの一通のエラーメール
ある日Google Search Console(以下、GSC)から以下のメールが届きました。
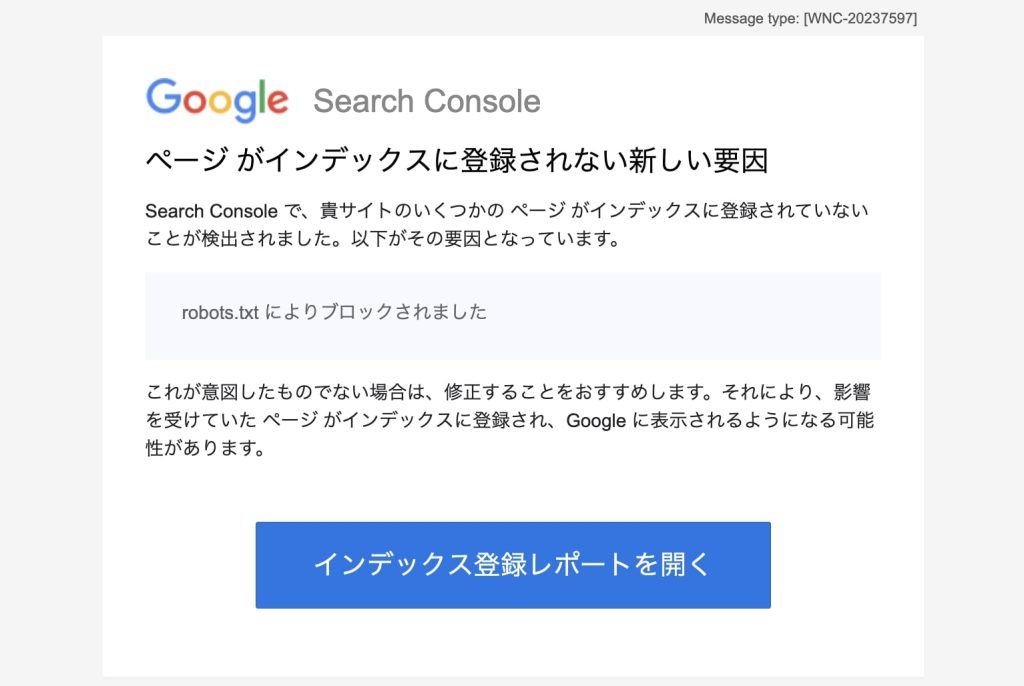
Search Console で、貴サイトのいくつかの ページ がインデックスに登録されていないことが検出されました。以下がその要因となっています。
robots.txt によりブロックされました
これが意図したものでない場合は、修正することをおすすめします。それにより、影響を受けていた ページ がインデックスに登録され、Google に表示されるようになる可能性があります。
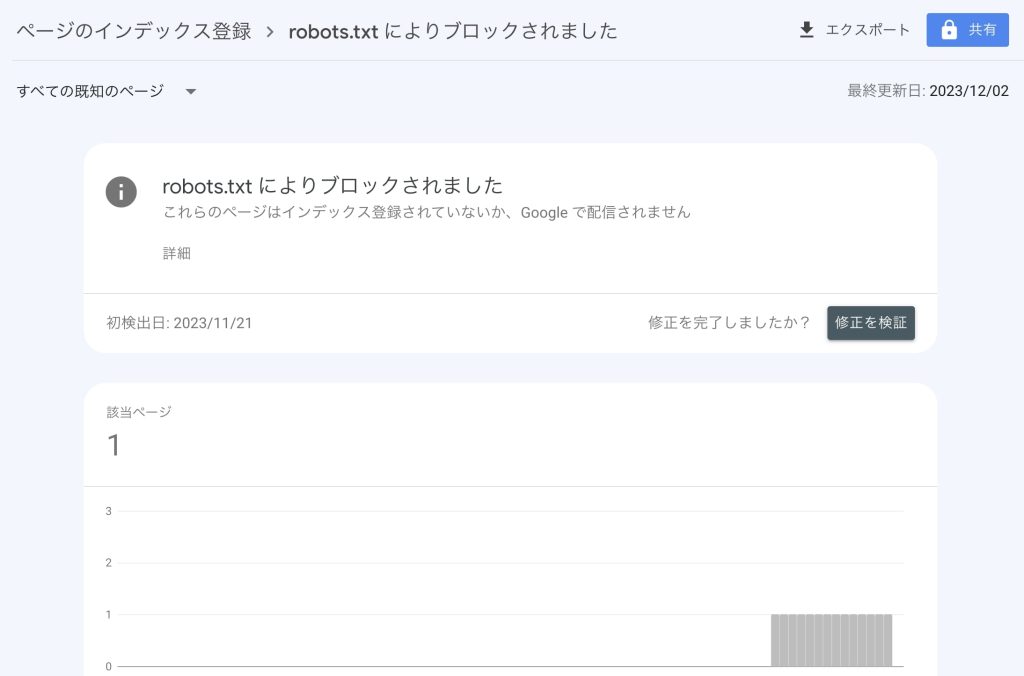
「robots.txtに書かれている内容により、該当ページがエラーになりましたよ」というエラー内容です。
あえてブロックしたページのため検索結果に表示されないで欲しい
本来はブロックされてしまったというわざわざ教えてくれる助かる通知なんですが、対象のページはただのサンプル掲載を目的としたページとなり、検索結果に表示されなくていいため、あえてrobots.txtに追加したページでした。このままでいい場合、どのように対応すればいいか調査しました。
そもそもrobots.txtは検索結果に表示されないようにするために利用するものではない
前提として、robots.txtファイルは検索結果に表示したくないページを指定するためのツールではない、とGoogleが公式に示しています。
robots.txt ファイルとは、検索エンジンのクローラに対して、サイトのどの URL にアクセスしてよいかを伝えるものです。 これは主に、サイトでのリクエストのオーバーロードを避けるために使用され、Google にウェブページが表示されないようにするためのメカニズムではありません。
robots.txt の概要とガイド | Google 検索セントラル | ドキュメント | Google for Developers
でも、robots.txt ファイルに”Disallow”ルールを設定することで、対象のファイルやディレクトリをクロールしないように設定できるので、少し矛盾しているようにも感じますし、わかりにくいですね。
noindexメタタグを使って検索結果に表示させないように設定する
検索結果に表示させないようにするには、Google公式にnoindexメタタグを使うと記載があります。
Google にウェブページが表示されないようにするには、noindex を使用してインデックス登録をブロックするか、ページをパスワードで保護します。
robots.txt の概要とガイド | Google 検索セントラル | ドキュメント | Google for Developers
よって、対象となるファイルに対して、<head>タグ内に<meta name="robots" content="noindex"> を追加します。
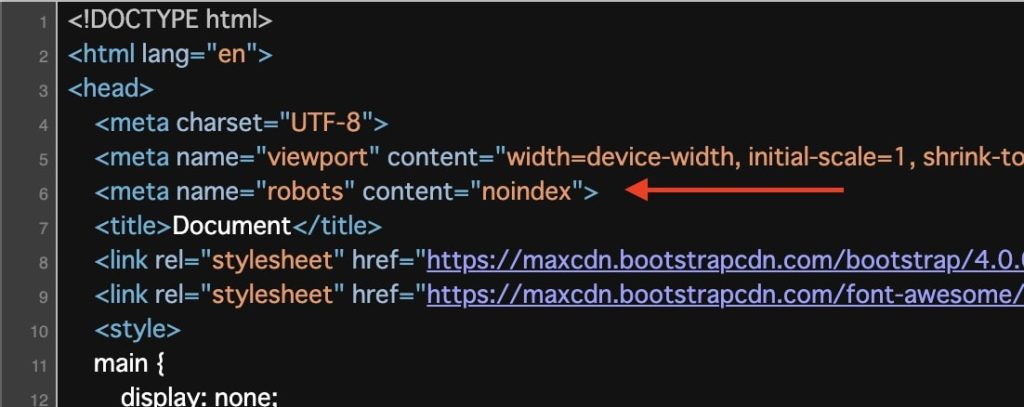
追記後、ファイルをアップロード。
数日経てばGSCに反映されるかもしれませんし、しれないかもしれません。特に大きいな問題ではないため、それでも通知されるようならスルーしましょう。もし意図的にページをrobots.txtでブロックしている場合、何もする必要はないという参考意見もあります。
対象ページによって対応するかどうかを決める
GSCでエラー通知があったのがわずかで、対象ページ自体の価値がないのであれば特に対応は不要かと思います。「何も対応しないのはなぁ……」という場合はnoindexタグを追加しましょう。
一方、対象ページが多い場合は対応しておくのが望ましいでしょうね。ケースバイケースで対応実施可否を決定するのがいいかと思います。




コメントを残す